Viimasel ajal olen pidanud oma Facebooki uudisvoogu sirvides mitu korda grimasse tegema: kõigepealt MMSi saaga peale, kus inimesed kasutasid enda ja oma laste ravimiseks mürgist ainet, ja täna ema peale, kes keeldus andmast keemiaravi oma ajukasvajaga tütrele ning “otsustas hakata tütart ravima end teenäitaja-terapeudiks kutsuva mehe näpunäidetel” (ma ei süüdista siin muidugi ainult ema — “teenäitaja-terapeut” kannab vähemalt sama palju süüd).
Aga kas tegu on ikka lollusega? On ju piisavalt näiteid sellest, kuidas inimkond on midagi arvanud ja siis paar hullu on näidanud, et see on vale (kusjuures need hullud on seejuures tugevalt hukka mõistetud): näiteks arstid hakkasid käsi desinfitseerima alles 19. sajandi lõpus. Kuidas peaksime tegema otsuseid olukorras, kus kõik ei ole mustvalge?
1. Tõenäosuslik maailmapilt
On vähe asju, milles saame kindlad olla. Kas oled täiesti kindel, et 1+1=2? Kui jah, siis kas sa oled täiesti täiesti täiesti kindel, et sa oled terve mõistuse juures ja pole matemaatikast valesti aru saanud ja 1+1 pole hoopis 3? Mida üldse tähendab täiesti kindel olemine?
Siin tuleb meile appi tõenäosusteooria. Võime iga väitega, näiteks “1+1=2” või “Maa läbimõõt on 8 meetrit” või “Taivo ei sure enne aastat 2050”, siduda arvu A, mis näitab, kui kindlad me selles väites oleme: olgu A suur, kui oleme väites väga kindlad, ja väike, kui me oleme väga kindlad vastupidises. Tuleb välja, et kui me sunnime A jääma vahemikku nullist üheni (0 ja 1 kaasa arvatud) ja paneme A-le veel kaks üsna intuitiivset piirangut, siis tuleb matemaatika hästi välja. Sellist arvu nimetame tõenäosuseks ja tähistame tavaliselt P-ga, mitte A-ga.
P iseenesest ei ole eriti intuitiivne: mida tähendab “tõenäosus, et kulli ja kirja visates jääb münt kulliga ülespoole, on 70%”? Selle tõlgendamiseks on kaks peamist lähenemist.
Frekventistid ütlevad, et nimetatud 70% tõenäosus tähendab, et kui viskaksime \(n\) korda (kus \(n\) on väga suur arv) münti, siis jääks \(0.7n\) korda kulliga ülespoole. Kui keegi annab meile mündi, mille kohta me midagi ei tea, siis kulli saamise tõenäosuse väljaselgitamiseks peame tegema väga palju katseid ja arvutama, kui suurel osal kordadest saime kulli.
Frekventism tundub väga loogiline ja on see lähenemine, mida koolis õpetatakse. Miks meil üldse midagi muud vaja on? Mõtle: kui paluksin sul ennustada, mis on tõenäosus, et homme sajab vihma, siis kuidas selle arvu leiaksid? Või kui peaksid ennustama tõenäosust, et Donald Trump saab USA presidendiks?
Probleem on selles, et tihti ei ole meil võimalik katseid läbi viia — näiteks teha USA presidendivalimisi 100 000 (sõltumatut!) korda, et vaadata, kui tihti Trump presidendiks saab. Kui me sellest tõkkest üle ei saa, siis peame väga tihti midagi ennustades lihtsalt käsi laiutama, mistõttu tahame leida parema tõlgenduse.
Bayesiaanlased ütlevad, et tõenäosus näitab subjektiivset uskumuse astet. Kui ütlen “selle mündiga kulli saamise tõenäosus on 70%”, siis see näitab minu subjektiivset hinnangut, mitte arvu, mis on objektiivne tõde universumi kohta. Kui mu hinnang kulli saamisele on 100%, siis mina arvan, et kirja ei ole võimalik mitte kunagi saada.
Bayesiaanluse jõud peitub selles, et minu hinnang sõltub sellest, kui palju ja milliseid tõendeid ma olen näinud. Kui olen üles kasvanud kodus, kus kõik mündid maandusid 95% ajast kirjaga ülespoole (see on hea trikk oma laste trollimiseks ajaks, kui nad koolis tõenäosust õpivad), siis on minu hinnang kullile väga madal. Samas otsustasid naabripoisi vanemad oma poega mitte trollida ja tema on näinud ainult ausaid münte1, seega tema hinnang kullile on palju kõrgem kui mul. Kumbki hinnang pole vale: need lihtsalt lähtuvad erinevatest tõenditest. (Kui ma suudaks selle nelja-aastastele selgeks teha, oleks kindlasti lasteaias palju vähem vaidlusi stiilis “minu isa on tugevam”.)
Aga kui see on subjektiivne hinnang, siis kuidas saame mina ja sina oma hinnanguid võrrelda; kumb on õige? Kas see tähendab, et igaühel on õigus oma arvamusele ja ükski pole vale? Ei. Igal inimesel või robotil või muul agendil võib olla oma hinnang mingi väite usutavusele, aga kahel ratsionaalsel agendil, kes on näinud samu tõendeid, peab see hinnang täpselt kattuma. Seega kui nii mina kui naabripoiss oleme pärit kodust, kus mündid on ausad, siis ilmselgelt eksin, kui ütlen, et kõik mündid maanduvad alati kirjaga ülespoole. Võime öelda, et naabripoisi hinnang on paremini kalibreeritud — ta hinnang on seninähtu valguses kõige parem.
Mis siis, kui ma ei ole üldse ühtegi tõendit näinud? Oletame, et lendan SpaceX-iga Marsile ja avastan kõigi ootuste vastaselt Marsi elaniku nimega Iilon, kes tutvustab mulle Marsil populaarset mängu nimega “mandiviskamine”: mant visatakse õhku ja maandudes võib ta jääda ülespoole kas küljega, kus on koll, või küljega, kus on kari. Kuna ma ei tea mandiviskamise kohta mitte midagi, siis tundub mõistlik arvata, et nii kolli kui karja tõenäosus on 50% — mul ei ole ühtegi põhjust kallutada oma hinnangut ei kolli ega karja poole.
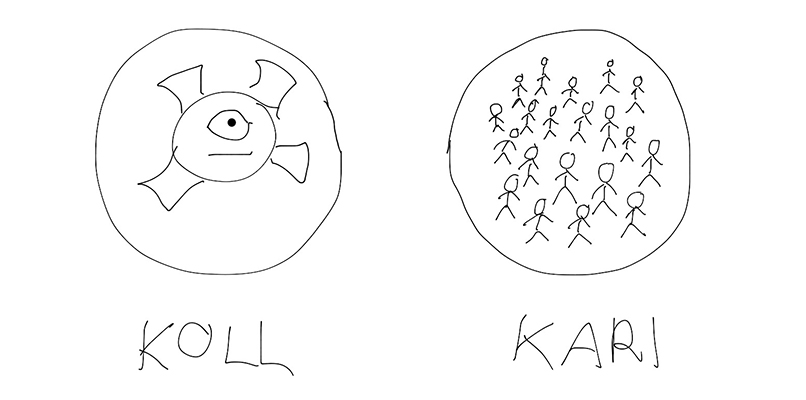
Mandi kaks poolt. Autor: Taivo Pungas ©®™
2. Bayes’i seadus
Nüüd võtab Iilon taskust mandi ja hakkab seda viskama. Esimene kord tuleb koll. Kuidas peaksin muutma oma hinnangut kolli tõenäosusele (meeldetuletus: enne viskamist oli see 50%)? Võrdleme kaht võimalikku universumit.
A) Mant on oma füüsikaliste omaduste tõttu natuke kallutatud kolli poole (s.t. koll tuleb natuke tihemini kui kari).
B) Mant on oma füüsikaliste omaduste tõttu natuke kallutatud karja poole.
Kuna me teame, et esimese viskega saime kolli, siis on universum A tõenäolisem: universum A klapib paremini sellega, mida jälgisin. Seega kui Iilon nüüd küsib, mis on mu hinnang kolli tõenäosusele, siis ütlen “natuke suurem kui 50%”.
Eelneva mõttekäigu saab formuleerida matemaatiliselt: Bayes’i seadus annab meile viisi, kuidas uusi tõendeid nähes oma hinnangut muuta. Bayes’i seadust kasutatakse väga paljudes statistilistes meetodites, masinõppes, tehisintelllekti ja robotite loomises ja paljudes muudes kohtades. Miks? Esiteks, see annab täpse reegli, kuidas reageerida uutele tõenditele, ja teiseks, see töötab nii teoorias kui praktikas.
Väga mitteformaalselt saab Bayes’i seaduse kokku võtta nii: kui mul on konkureerivad hüpoteesid A ja B, mingi eelhinnang kummagi tõenäosusele ja äkitselt saabuvad tõendid, mis toetavad üht või teist hüpoteesi, siis mu uus hinnang sõltub kahest asjast: eelhinnangust ja tõenditest.
Kuidas? Proovin anda intuitsiooni — valemi täpne matemaatiline kuju pole raske, aga ideest saab ka ilma selleta aru2.
Näide 1: kas praegu on öö või päev?
Ärkan pärast operatsiooni haiglapalatis. Tahan otsustada, kas parasjagu on väljas öö või päev; kuna võisin olla väga pikka aega narkoosi all, siis ei ole mul mingit infot kellaja kohta ja pean öö/päev otsuse tegema selle põhjal, mida palatis näen.
Äkitselt torkab mulle pähe idee vaadata aknast välja — valguse järgi on väga lihtne kellaaega ennustada. Park, mida läbi akna näen, on valgusega üle valatud.
Tahan otsustada, kas on öö või päev, seega omavahel võistlevad hüpoteesid A := “praegu on öö” ja B := “praegu on päev”3. Enne aknast välja vaatamist on mu hinnang, et A ja B on võrdtõenäolised (sest ma ei tea kellaaja kohta midagi), s.t. P(A) := 50% ja P(B) := 50%. Siis saabub tõend := “väljas on väga valge”.
Bayes’i seaduse järgi peaks mu uus hinnang olema:
- kõrge nendele hüpoteesidele, mis seletavad tõendeid hästi;
- madal nendele hüpoteesidele, mis seletavad tõendeid halvasti.
“Praegu on öö” seletab väga halvasti tõendit “väljas on väga valge”. “Praegu on päev” seletab väga hästi tõendit “väljas on väga valge”. Seega on mu uus hinnang: “P(A) on madal ja P(B) on kõrge” ehk inimkeeli: praegu on väga tõenäoliselt päev.
Näide 2: kas Alice armastab mind?
Maailmas on kahte sorti inimesi: need, kes mind (romantilises mõttes) armastavad, ja need, kes ei armasta. Olen päris kindel, et väga suur osa inimestest, kellega kokku puutun, ei armasta mind.
Oma sünnipäeval tööle minnes ja kolleegidega torti nautides tuleb üks töökaaslane — nimetame teda Alice’iks –, annab mulle lilled ja sooja kallistuse. Kas ta armastab mind?
Ma tean, et see näide kõlab nagu 6-aastaste lasteaialaste jutt abiellumisest, aga selline olukord — signaalide valestitõlgendamine inimsuhetes — on nii tüüpiline, et tasub märkimist.
Omavahel võistlevad hüpoteesid A := “Alice armastab mind” ja B := “Alice ei armasta mind”. Kuna enamik mu tuttavatest mind ei armasta, siis on mu eelhinnang A-le väga madal — võtame näiteks P(A) := 0.1% ja P(B) := 99.9%.
Nüüd saabub tõend “Alice annab mulle lilled ja kallistab mind”. Tuletame meelde Bayes’i seadust: tõenäosus on
- kõrge nendel hüpoteesidel, mis seletavad tõendeid hästi;
- madal nendel hüpoteesidel, mis seletavad tõendeid halvasti.
A = “Alice armastab mind” seletab väga hästi, miks ta mind nii eriliselt kohtles. B = “Alice ei armasta mind” seletab ka erilist kohtlemist üsna hästi — võib-olla on ta lihtsalt tore inimene –, aga A seletab tõendeid natuke paremini. Seega järeldan, et päris kindlasti Alice armastab mind…
…oot-oot, see ei tundu loogiline. Kui kõigist mu tuttavatest ainult 0.1% ehk iga tuhandes mind armastab, siis kuidas ma sain hüpata järelduseni, et Alice mind peaaegu kindlasti armastab? Ma tegin vea: jätsin arvesse võtmata eelhinnangud. Tegelikult ütleb Bayes’i seadus, et tõenäosus on
- kõrge nendel hüpoteesidel, mis seletavad tõendeid hästi JA mille eelhinnang oli kõrge (mida pidasime juba enne tõenäoliseks);
- madal nendel hüpoteesidel, mis seletavad tõendeid halvasti JA mille eelhinnang oli madal.
Proovime uuesti. A eelhinnang on väga madal ja ta seletab tõendeid üsna hästi. B eelhinnang on väga kõrge ja ta seletab tõendeid natuke halvemini. Kuna B eelhinnang on nii palju — 1000 korda — kõrgem kui A eelhinnang ja tõendid on üsna nõrgad, siis võime üsna turvaliselt öelda, et meie uus hinnang B-le pärast tõendite nägemist on ikkagi väga kõrge.
Selle näite saab kokku võtta nii: kui keegi sulle koridoris vastu tulles silma vaatab ja naeratab, siis ta tõenäoliselt ei ole sinust sisse võetud, sest enamik inimesi ei ole sinust sisse võetud. (Mu primaadiaju on mind nii palju sellesse lõksu meelitanud, et ma pean seda vastulauset endale tihti meelde tuletama.)
Näide 3: kas ma olen osav autojuht?
Maailmas on kolme sorti autojuhte: osavad, keskmised ja kobad autojuhid. Enamik autojuhte — 80% — on keskmised; nii osavaid kui kobasid on 10%.
Ma arvasin, et olen keskmiselt hea autojuht, aga siis põhjustasin kerge liiklusõnnetuse. Milline autojuht ma olen?
Nüüd on meil kolm konkureerivat hüpoteesi, aga idee on täpselt sama.
A := “ma olen koba”, B := “ma olen keskmine”, C := “ma olen osav”. Eelhinnang on P(A) = 10%, P(B) = 80%, P(C) = 10%. Tõend on “põhjustasin kerge liiklusõnnetuse”.
Kõige paremini seletab tõendit hüpotees A — kobad autojuhid põhjustavad üsna tihti õnnetusi. B seletab tõendit halvemini — keskmised autojuhid põhjustavad vähem õnnetusi kui kobad, aga see pole kindlasti ka võimatu. C seletab tõendit kõige halvemini — osavad autojuhid ei põhjusta peaaegu üldse õnnetusi. Seega P(C) väheneb, P(B) väheneb natuke ja P(A) kasvab. Näitan suvaliste arvude väljamõtlemise asemel parem joonist:

Eelhinnang (vasakul) näitab juba enne mainitud 10-80-10 jaotust. Uus hinnang (paremal) näitab jaotust, kus hüpoteesi “ma olen koba” tõenäosus on natuke kasvanud ülejäänud kahe hüpoteesi arvelt. Poleks ikka pidanud avariid põhjustama!
Pidev skaala
Kõigi autojuhtide ainult kolme klassi jaotamine tundub natuke kunstlik. Kui tahame autojuhtide oskust kirjeldada pideval skaalal — näiteks nullist 10-ni, kus 10 näitab väga osavat juhti ja 0 täielikku kobakäppa –, siis saame täpselt samamoodi rakendada Bayes’i seadust. Ainuke erinevus on, et nüüd on meil hüpoteese lõpmatu arv: iga taseme jaoks — näiteks 2 või 7.4094582 — on meil eraldi hüpotees. Sel põhjusel kasutame tõenäosustihedust, mis on meie praeguse otstarbe jaoks sama, mis tõenäosus4.
Oletame, et meil ei ole mingit eelinfot selle kohta, kus ma autojuhtide oskuse skaalal asun. Siis on mõistlik võtta eelhinnanguks, et kõik hüpoteesid on võrdtõenäolised, teisisõnu: meil pole aimugi. Graafiliselt näeb see välja nii:

Siin näitab horisontaaltelg erinevaid hüpoteese selle kohta, kui osav autojuht Taivo on, ja vertikaaltelg on tõenäosustihedus.
Nüüd saame tõendi “Taivo võitis Maanteeameti Osava Juhi Auhinna”. See on palju tõenäolisem universumis, kus Taivo on osav juht, seega uuendame oma hinnangut:

Nagu näha, on tõenäosusmass (see lilla värk graafikul) vormunud ümber ja liikunud rohkem paremale poole. Sellest graafikust võib mõelda nagu panuselauast: kui me peaksime panustama raha sellele, milline juht ma olen, siis võidaksime kõige rohkem, kui tekitaksime teljele täpselt sellise kujuga mündihunniku. Kuna meil on lõplik hunnik münte (lilla ala pindala5 peab alati olema täpselt 1), siis paremale poole tõenäosusmassi lisamiseks peame selle kuskilt võtma — seetõttu jääb vasakul tõenäosusmassi vähemaks.
Nüüd saame tõendi “Taivo sõitis eile aiast välja tagurdades aiaposti paigast”. See on tõenäolisem universumis, kus Taivo pole eriti hea juht, seega uuendame oma hinnangut jälla allapoole:

Nüüd saame tõendi “Taivo sõitis täna hommikul otsa pargitud autole”. Me teame, mida teha:

Kui nüüd saame kahe kuu jooksul järjepidevalt tõendeid selle kohta, mida Taivo autoroolis teinud on (nii head kui halba), siis saame olla aina kindlamad, et meie hinnang on hea, s.t. oma panust aina kitsendada:

Ja niimoodi pikka aega edasi jätkates saame veel kindlamad olla, et meie hinnang Taivo osavusele on täpne:

Praeguseks arvame, et Taivo asub osavuse skaalal väga tõenäoliselt umbes 3 ja 3.7 vahel.
Bayes’i seadus on sellepärast äge, et saame seda rakendada piiramatult palju kordi järjest. Kui töökaaslane toob kõigepealt lilli ja suudleb mind põsele (misjärel on mu hinnang sissevõetusele “üsna tõenäoline”), aga siis ütleb, et ta on abielus ja see oli ainult sõbralik žest, siis saan uuendada (ja pean uuendama!) oma hinnangut sissevõetusele, näiteks “ebatõenäoliseks”.
Üks kõige tihemini nimetatud probleem Bayes’i seadusega on see, et tõendeid nähes saame küll hinnangut uuendada, aga selleks peab meil juba mingi eelnev hinnang olema — nimetame seda eelhinnanguks6, inglise keeles prioriks. Aga: kui me pole ühtegi tõendit näinud, siis kust peaksime eelhinnangu võtma?
Mandiviskamisel võtsime eelhinnanguks 50%-50% tõenäosused. Enamasti ongi olukorras, kus me probleemi kohta midagi ei tea, mõistlik võtta eelhinnang võimalikult vähehuvitav: enamiku müntide puhul on mõlemad pooled võrdsed; praegu 3-kuune beebi on tulevikus tõenäoliselt keskmine autojuht7; suvaline töökaaslane pigem ei armasta mind.
Lõpetan selle peatüki metafooriga, mis jõudis minu teadvusse Less Wrongist. Samamoodi, nagu Google Maps või suvaline maakaart ainult kujutab reaalsust ja autoteed tegelikult ei ole kollased murdjooned, on minu hinnangud ainult kaart sellest, milline on päris maailm — need võivad olla õiged või valed. Kaardi parandamine on järk-järguline tegevus: tõendite saabudes uuendan oma kaarti ja mida rohkem tõendeid kogun, seda täpsem mu kaart (loodetavasti8) on. On selge, et kolmest allolevast kaardist on minu joonistatu kõige ebatäpsem ja samamoodi saame öelda, et ühe inimese peas olev kaart reaalsusest on ebatäpsem kui teiste oma.9
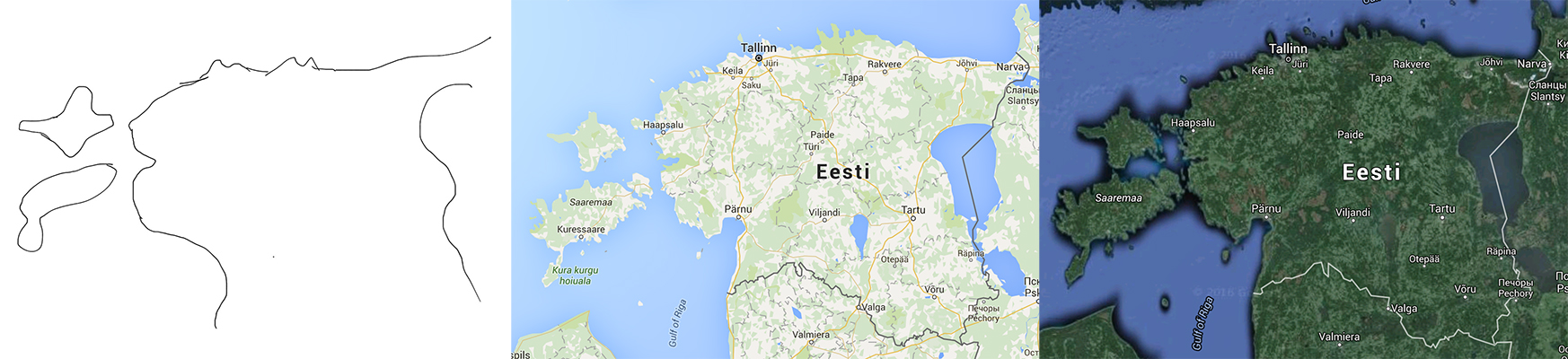
Erinevad Eesti kaardid (vasakult paremale): a) Taivo (mälu järgi) joonistatud kaart, b) Google’i kaart ja c) Google’i satelliitkaart
Kuidas me asju teame?
Nagu kirjutasin, saab bayesiaanlikku mõtteviisi väga edukalt kasutada ükskõik millise küsimuse hindamiseks, näiteks “kas suitsetamine tekitab vähki”. Või:
A = “MMS (mille aktiivne toimeaine on kloordioksiid) on inimestele kahjulik”,
B = “MMS ei ole inimestele kahjulik”,
eelhinnang = {A: “tõenäoline”, B: “ebatõenäoline”} (Seletus: kõigist klooriühenditest Maal on peaaegu kõik mürgised; samamoodi kõigist anorgaanilistest kloorühenditest on peaaegu kõik mürgised.),
tõendid = “kui ma MMS-i enda nahale määrin, siis nahk läheb punaseks ja hakkab valutama; kui ma seda oma lapsele toidan, siis hakkab tal kõht valutama”,
uus hinnang = {A: “väga tõenäoline”, B: “väga ebatõenäoline”}.
A = “teenäitajad-terapeudid aitavad inimesi vähist tervendada”,
B = “teenäitajad-terapeudid ei aita inimesi vähist tervendada”
eelhinnang = {A: “väga ebatõenäoline”, B: “väga tõenäoline”} (Seletus: enamik asju, näiteks kiviga pähe löömine, õhtukooli saatmine või palga tõstmine, ei aita inimesi vähist tervendada — väga vähesed asjad aitavad.),
tõendid = “paranormaalsete nähtuste demonstreerimise eest väljaantavaid auhindu ei ole mitte keegi mitte kunagi saanud”,
uus hinnang ={A: “veel vähem tõenäoline”, B: “veel rohkem tõenäoline”}.
Kas oskame nüüd öelda, kus MMS-i, nõiaravisse ja maagilistesse ehetesse uskuvad inimesed pange panevad? Minu pakkumine on, et neil on eelhinnang paigast ära.
Mõistlikel agentidel on pea alati eelhinnang stiilis “X ei oma imeliselt kasulikku efekti Y” ja seda kõigi auru transformaatorite, kundalinikraanade ja chakrakoppade jaoks. Ülejäänud ilmselt ei mõtle, mis nende eelhinnang võiks olla või on see mingil põhjusel paigast ära ja seega jäävad üsna kergesti uskuma ükskõik millist hüpoteesi, mida parajasti peavoolumeedia alla surub, pahad valitsused varjavad ja millelt kurjad korporatsioonid kasu lõikavad.
Kaanepilt: Endless Forms Most Beautiful, avaldatud litsentsi CC BY-NC-SA all. Originaali on siin modifitseeritud.
Jaga:
Märkused
- Selliseid, mis maanduvad 50% ajast kirjaga üles ja 50% ajast kulliga üles.
- Põhjalikumaks käsitluseks soovitan lugeda Sivia (2006) esimest kolme peatükki.
- Koolon-võrdusmärk tähendab, et omistan väärtust: X := 3 tähendab “olgu X nüüd 3”. Lihtsalt võrdusmärk tähendab, et väidan midagi: X=3 tähendab “Taivo väidab, et X on 3.”
- Tegelikult on tõenäosustihedus \(f\) ja tõenäosus \(P\) seotud nii: tõenäosus, et tase on vahemikus näiteks 4-st 6-ni, on \( P(\{4 \leq t \leq 6\}) = \int_{t=4}^{t=6} f(t) dt \), kus \(t\) tähistab taset.
- Pindala on tõenäosustiheduse integraal rajades \(-\infty\) kuni \(\infty\); kuna siin kasutan otstest tõkestatud beetajaotust, siis võime rajadeks võtta selle asemel 0 ja 10.
- Leidsin siit tõlke “eeltõenäosus”, aga “eelhinnang” suupärasem.
- Kuigi ei usu, et tal eriti autot juhtida vaja on — 18 aastaga võiksid isesõitvad autod massidesse jõuda.
- Eeldusel, et ma oskan tõendeid õigesti kasutada. Kui aktsepteerin ainult tõendeid, mis mu eelhinnangut kinnitavad ja lükkan tagasi kõik, mis sellele vastu käib, siis ei saa mu kaart kunagi eriti täpseks. Selle fenomeni nimi on confirmation bias.
- Kaardi täpsus iseenesest ei pruugi sulle oluline olla — tõepoolest, ilmselt poleks enamikul meist midagi teha väga detailse maakaardiga tükikesest Amazonase vihmametsast — pigem see, mida sellega teha saad. Täpne kaart on hea siis, kui ta aitab teha paremaid otsuseid, ja sel põhjusel tahame, et meie peas olevad hinnangud kattuksid võimalikult täpselt reaalsusega — mitte sellepärast, et meile meeldiks väga statistika.
Väga hea ülevaade!
Täiendaksin, et matemaatiliselt käituvad mõlemal moel hinnatud tõenäosused ühesuguselt (nt sõltumatute sündmuste puhul saab lihtsasti korrutada jne). Erinevus on filosoofilises lähenemises: kas tõenäosus on entiteedi omadus (objektivistilik lähenemine) või meie oletus (subjektivistlik). Nt kas see, kui me ‘teame’, et münt on hästi balansseeritud, on mündi omadus või meie oletus.
Hea ülevaate saab Galavotti “Philosophical introduction to probability” ja Stanfordi filosoofialeksikonist. Lisaks enimlevinud frekventistlikule ja bayesilikule lähenemisele on ka muid filosoofilisi tõlgendusi (nt logitsistlik).
Bayesiliku lähenemise kasutamine võib tunduda problemaatiline, kui mingi uskumus on raudne (eeljaotus on koondunud P(X) = 0 või P(X) = 1) — sel juhul ei muuda lisanduvad tõendid meie arvamust mitte kuidagi.
Hea point — jätsin mainimata, et matemaatilist vahet ei ole.
Äärejuhtudega P(X)=0 või P(X)=1 ei muuda tõesti Bayes’i meetodit kasutades tõendid midagi. Aga minu meelest on see ka mõistlik — võimegi öelda, et P(X)=0 tähistab meie hinnangut “X on täiesti võimatu, ükskõik mida ma näen”. Ja lisaks meenutab, et määrata mingi sündmuse tõenäosus 0-ks (või 1-ks) on nii ekstreemne, et peaksime väga tõsiselt kaaluma, kas see on ikka õige.