Masinõpe (machine learning) oli 2016. aastal haibitsükli tipus. Eesti on ses osas ilmselt veidi taga, aga Eesti masinõppe kokkusaamiste populaarsuse põhjal mitte väga kaugel. Tean oma (mitte ainult tehnoloogiaettevõtetes töötavate) tuttavate kaudu, et huvi selle suuna vastu on märkimisväärne.
Mis on masinõpe?
Wikipediast tõlkides: masinõpe on arvutiteaduse haru, mis annab arvutitele õppimisvõime ilma neid otseselt selleks programmeerimata. Kõige produktiivsem seletus ongi võrdlus programmeerimisega: kui tavalise IT-arenduse puhul teame nii soovitud tulemust (“leia kõige odavam võimalik lennukipilet soovitud päeval”) kui ka viisi selle saavutamiseks (“küsi andmebaasist kõik võimalikud piletid, järjesta hinna järgi kasvavalt ja kuva esimene tulemus”), siis masinõpe ründab tavaliselt selliseid probleeme, kus eesmärk on hästi teada (“leia pildil kõik näod”), aga isegi eksperdid ei oska väga hästi öelda, kuidas sinna jõuda.
Teine kasulik võrdlus on klassikalise statistikaga. Siin on piir hägusem – masinõpe asub arvutiteaduse ja statistika puutepunktis ja statistika on palju laiem ala kui masinõpe –, aga mulle tundub, et masinõpe on rohkem inseneri lähenemine. Mõtlen sellega, et masinõppes on põhiline edu indikaator mudeli kvaliteet (Mitu protsenti vähijuhtumitest suudame mikroskoobipildi pealt tuvastada? Kui suur osa meie väidetud vähihaigetest on tegelikult terved?), aga statistikas interpreteeritavus ja matemaatiline vettpidavus (Mille põhjal otsuse tegime? Kas kõik tehtud eeldused kehtivad?). Masinõpe aktsepteerib rohkem musta kasti stiili, kus kasti sisu pole nii oluline – peaasi, et see teeb, mida vaja.
Klassikaliselt jaotatakse masinõppe ülesanded kolmeks:
- juhendatud õpe (supervised learning),
- juhendamata õpe (unsupervised learning),
- stiimulõpe (reinforcement learning).
(Muide, masinõppe terminite jaoks on olemas neurovõrkude ja masinõppe sõnastik.)
Juhendatud õpe
Igasugune masinõpe vajab andmeid, seega alustame nendest. Vaatame näiteks allolevat tabelit erinevate pankade töötajatest. Iga töötaja on üks andmepunkt (data point) ja igaühe kohta teame ta nime, sugu, tööandjat, vanust, koormust ja brutopalka – need on tunnused (features). On hea tõenäosus, et kui võtad ette suvalise andmebaasi, on sealsetes tabelites iga rida üks andmepunkt ja tulpades on tunnused.
| Nimi | Sugu | Tööandja | Vanus | Koormus | Brutopalk |
| Helve | N | Swedbank | 52 | 0.8 | 1200 |
| Tarmo | M | SEB | 39 | 1.0 | 1350 |
| Aimar | M | Swedbank | 32 | 1.0 | 1240 |
| Tatjana | N | LHV | 29 | 0.5 | 940 |
| Tarmo | M | LHV | 40 | 1.0 | 1600 |
(Tavaliselt on meil viie andmepunkti asemel tuhandeid.)
Juhendatud õppe eesmärk on luua mudel, mis võtab sisse andmepunkti ja ennustab selle kohta midagi. Töötajate näite puhul võiksime üritada ennustada ülejäänud tunnuste põhjal töötaja palka, aga see pole ainus variant – võiksime ka ennustada hoopis vanust või sugu sõltuvalt sellest, mida parasjagu teada tahame.
Seda tunnust, mille ennustamine meid huvitab, kutsume märgendiks (label või target) või, kui märgend saab võtta lõpliku hulga väärtusi (näiteks ennustame töötajate sugu), siis klassiks ja vastavat tegevust klassifitseerimiseks.
Niisiis: juhendatud õppe eesmärk siin kontekstis on luua etteantud andmetabeli põhjal programm, mis võtab sisse ükskõik millise kombinatsiooni – näiteks {Peeter, M, SEB, 44, 0.6} – ja annab välja brutopalga, kusjuures maagiline osa on, et me saame ennustada palka ka inimestele, keda me kunagi näinud pole! (Muidugi juhul, kui mudel korralikult töötab.)
Palgaennustamine ei pruugi olla kõige kasulikum rakendus, aga sama lähenemisega võiks ennustada näiteks (tunnused -> märgend):
- Korteri asukoht, üldpind ja seisukord -> korteri hind.
- Inimese vanus, sugu, sissetulek, riik -> lemmik-tootekategooria Amazoni e-poes.
- Kasutaja päritoluriik, krediitkaardimaksete arv kuus, maksete kogusumma kuus -> kas tegu on petisega. (Seotud esitlus TransferWise’ilt.)
Juhendatud õpe katab ka keerulisemaid stsenaariume. Masinõpe on viimasel ajal nii palju tähelepanu saanud just sellepärast, et mudelitesse saab sisse sööta müraseid toorandmeid (näiteks pilte või teksti) ja need töötavad sellegipoolest hästi.
- Pilt -> klass: näiteks “kas sellel valvekaamera pildil on illegaalne piiriületaja või mitte” (Eesti piirivalve on seda lähenemist katsetanud).
- Pilt -> mitu märgendit: näiteks “tuvasta kõik näod sellel pildil“.
- Pilt -> märgend iga piksli kohta: näiteks “tuvasta sel pildil vaba teepind, jalakäijad, liiklusmärgid ja teised autod“.
- Tekst -> klass: näiteks “kas see e-kiri on spämm või mitte”.
- Tekst -> märgend: näiteks “kui positiivne on see tootekommentaar Amazonis”.
- Tekst -> tekst: näiteks “võta see Postimehe artikkel ühe lausega kokku”.
{kind=link}
Juhendatud õppe (ja üldiselt masinõppe) ülesannete keerukus varieerub kõvasti. Näiteks käekirja piltidest numbrite tuvastamises on parimad mudelid juba inimese tasemel, aga tekstist kokkuvõtete tegemises veel kaugel maas.
Juhendamata õpe
Juhendamata õpe erineb juhendatud õppest selle poolest, et… (trummipõrin) juhendajat ei ole. See tähendab, et me ei ürita enam ennustada mingit konkreetset muutujat – töötaja palka, korteri hinda või inimese lemmik-aluspükste brändi. Mis siis üle jääb?
Juhendamata õppe eesmärk on leida andmetest struktuuri. See tähendab tavaliselt järgneva kolme küsimuse uurimist.
Mis on levinud ja mis esineb harva?
Kui me teame, kuidas andmepunktid on jaotunud, saame öelda, mis on normaalne ja mis on veider või ootamatu. Anomaaliate tuvastamine (anomaly detection) on kasulik näiteks küberrünnakute tuvastamisel: oletame, et meil on veebileht, kus mõõdame iga minuti tagant külastajate hetkearvu ning külastajate päritoluriikide arvu. Pärast paari päeva saame kõik need mõõtmised panna graafikule:
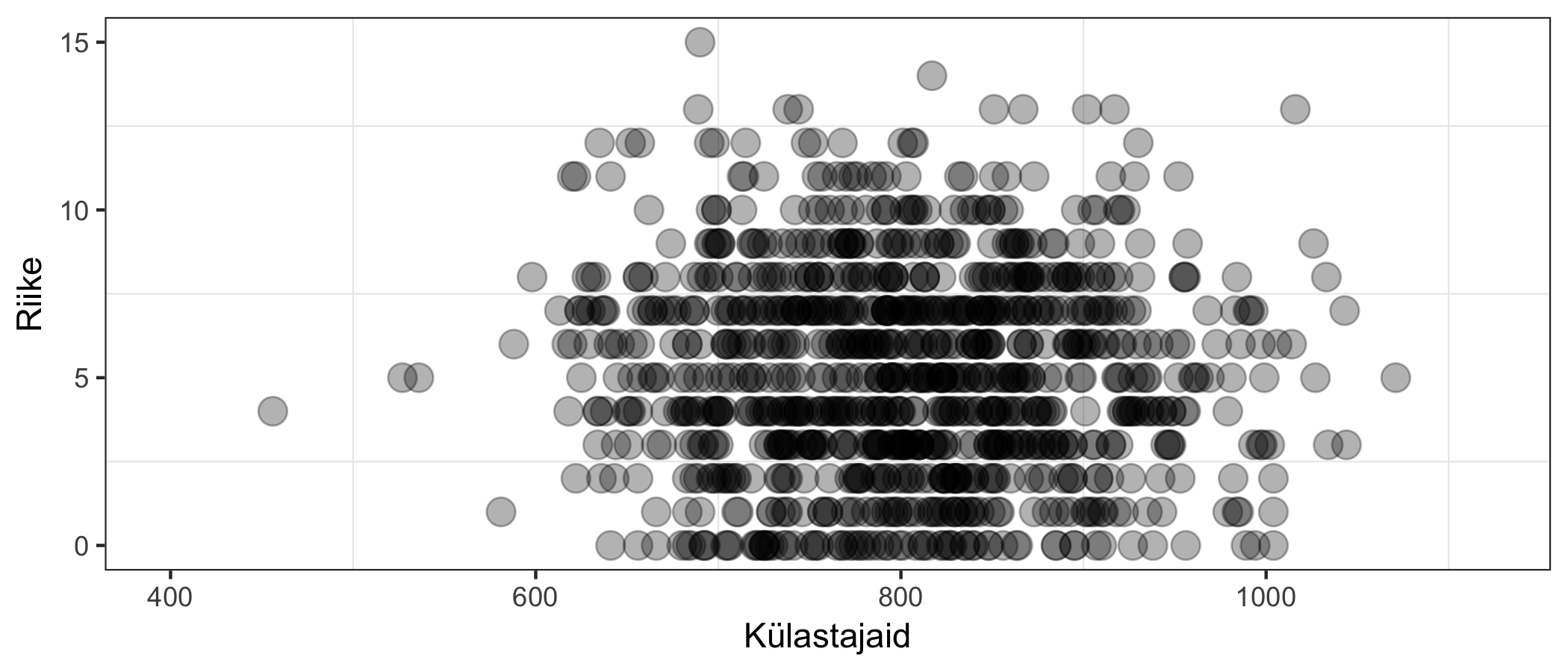
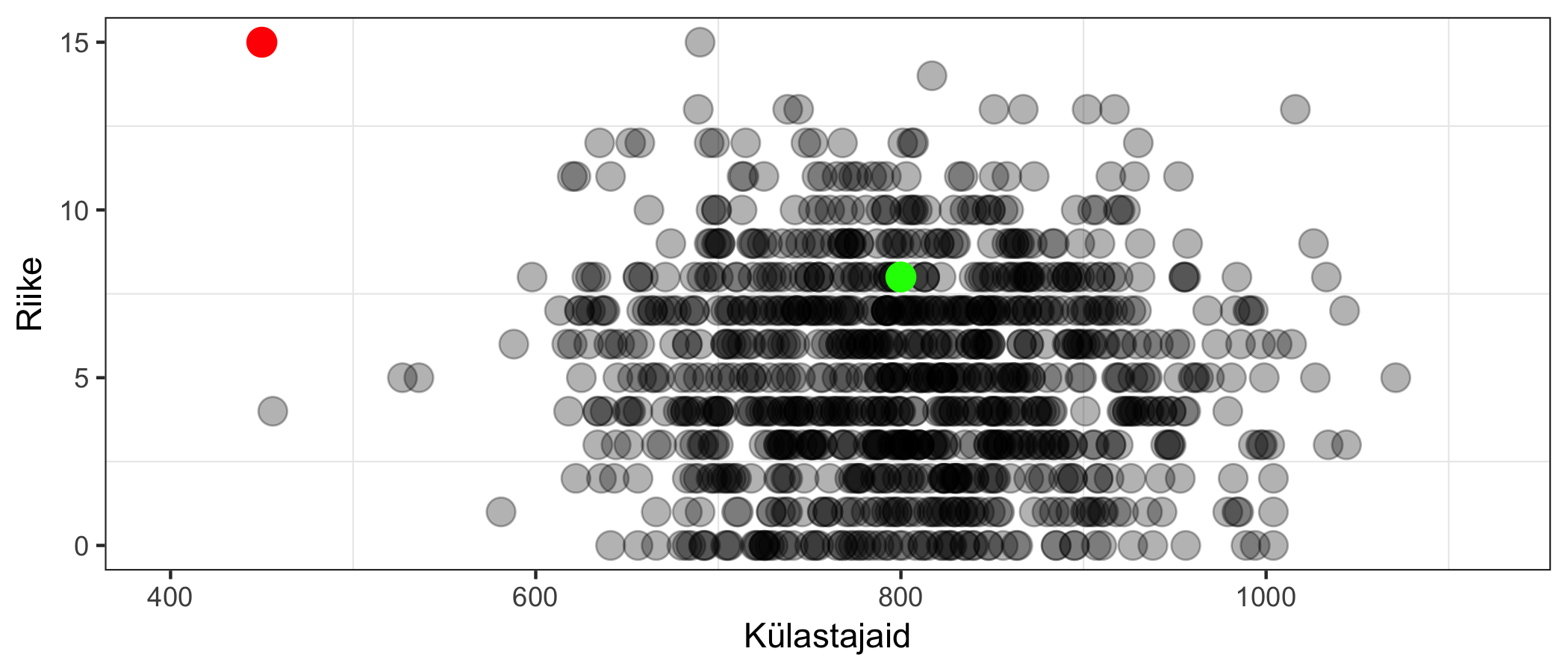
Nüüd saame teha reegli, mis lihtsustatult on: “kui oleme väljaspool normaalset piirkonda, teavitame süsteemiadministraatorit võimalikust rünnakust”. Roheline punkt allpool on normaalne käitumine, aga punase punkti puhul peaks ekspert asja lähemalt uurima. See on muuhulgas näide olukorrast, kus masin ei tee lõplikku otsust, vaid aitab vähendada vajadust inimtööjõu järele, kuna filtreerib välja ebaolulist infot.
Kas saame andmepunktid jaotada loomulikult esinevatesse gruppidesse?
Meil on veebipood, kus mõõdame iga kliendi jaoks a) aastast ostude arvu ja b) keskmist ostusummat:
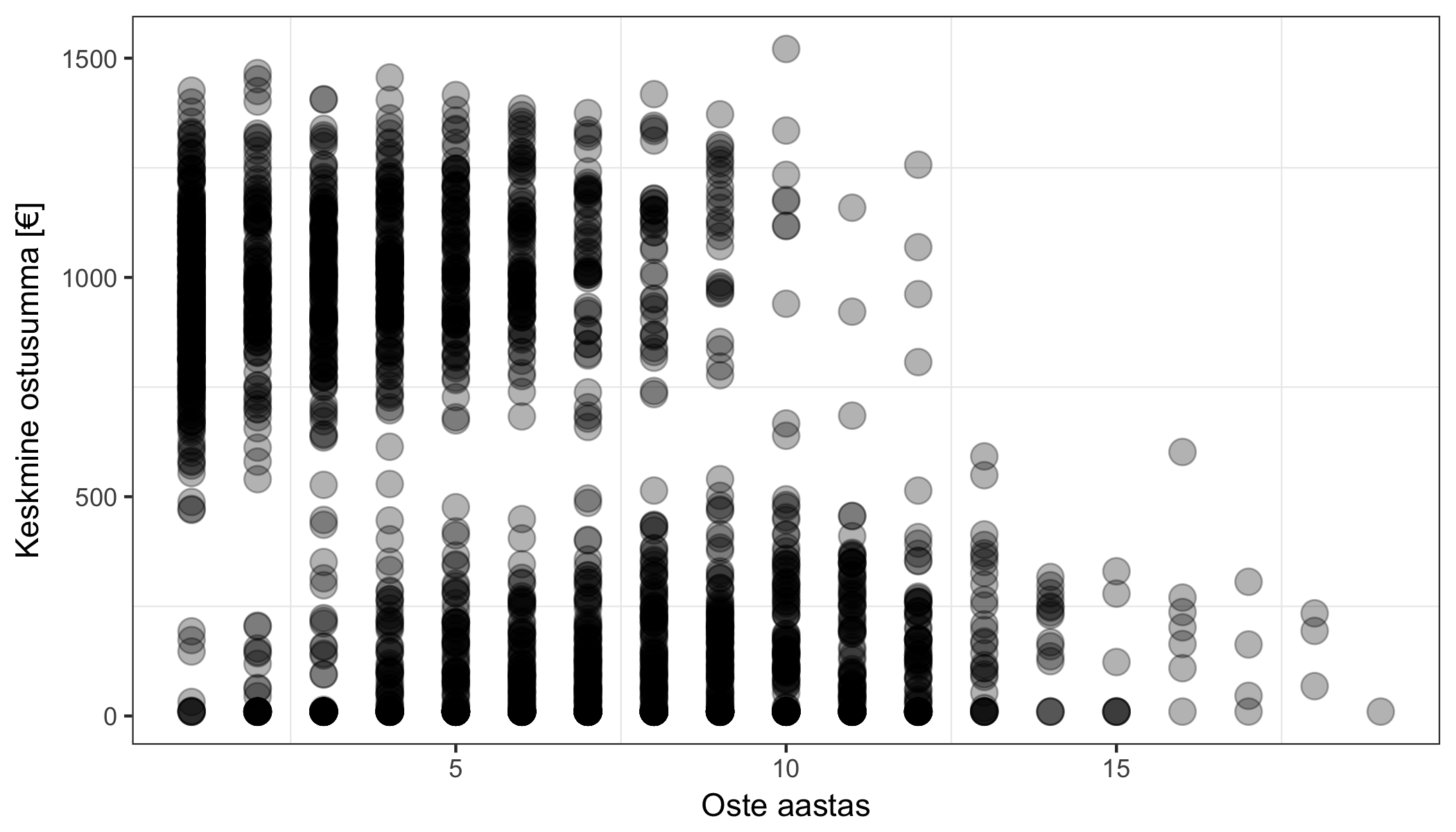
Võib-olla näed juba silmaga, et graafikult tulevad välja kaht tüüpi kliendid: ühed ostavad iga kuu natuke, teised kord aastas palju – selle teadmisega saame teha turundust (näiteks meilikampaania teel) kummalegi grupile erinevalt. Saame sellist analüüsi teha automaatselt – vastava tegevuse nimi on klasterdamine (clustering):
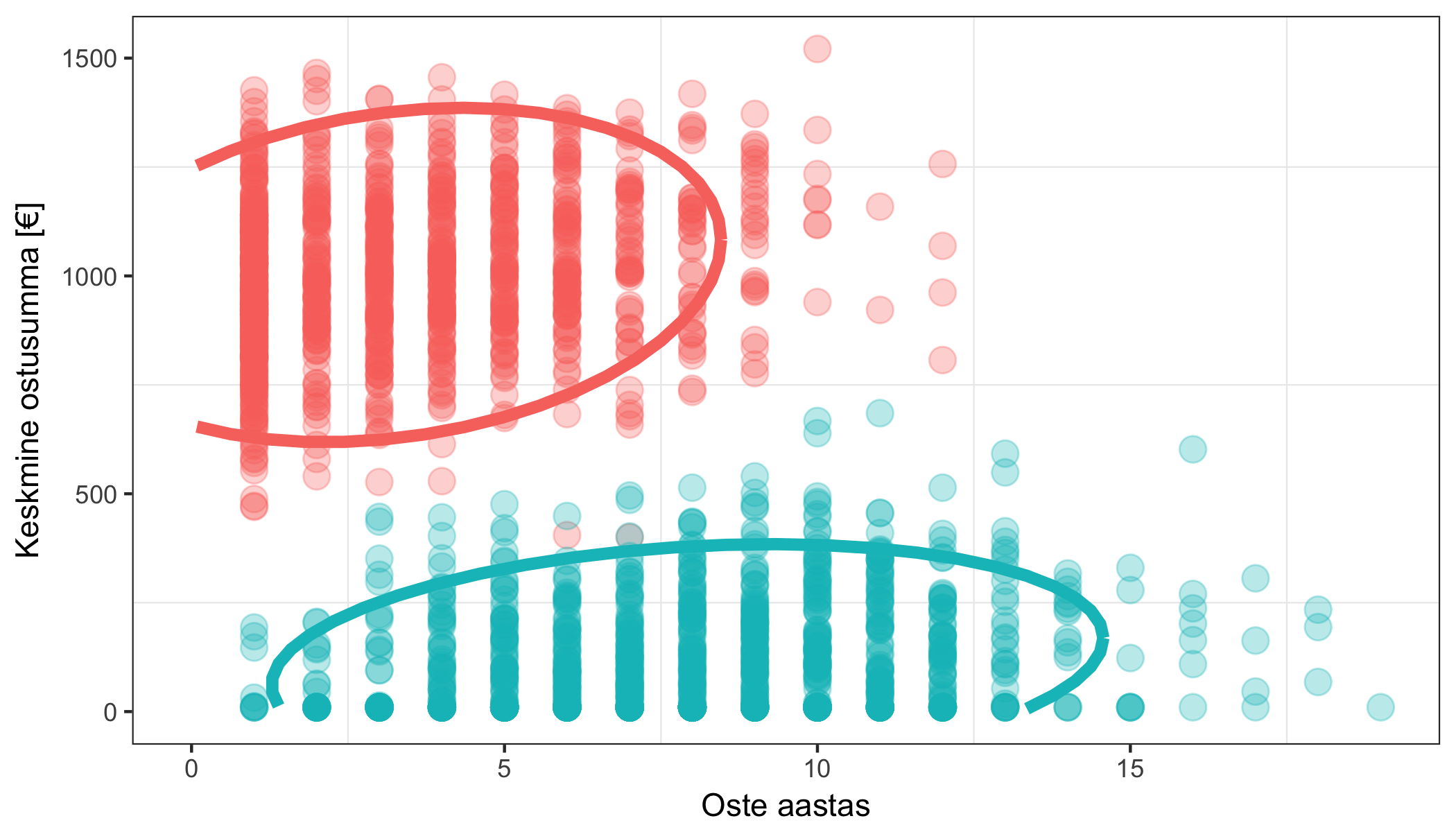
Muide, nendes näidetes võib masinõpe tunduda kasutu, sest joonis on kahemõõtmeline ja inimene saab ühe pilguga ülesande lahendatud, aga tihti on tunnuseid kümneid või sadu ja sel puhul inimintuitsioon ei aita.
Kas saame leida peidetud struktuuri?
Paljude tunnustega andmete visualiseerimine on keeruline: kuidas joonistada kasulikult 80-mõõtmelist graafikut? Selle jaoks võime vähendada mõõtmeid (dimensionality reduction): teisendada andmed kujule, kus tunnuseid on ainult 2-3 ning iga uus tunnus on mingi kombinatsioon originaaltunnustest.
Üsna ekstreemne näide sellest on piltide asetamine kahemõõtmelisele skaalale: sadadest piksliväärtustest peame saama kaks koordinaati. Just seda tegi ühe suurema projekti käigus sügavõppe ekspert Andrej Karpathy (kui vaatad lähemalt, siis saad aru, et mingil viisil sarnased pildid asuvad üksteisele lähemal):

Lisaks visualiseerimisele aitab peidetud struktuur ka teistmoodi. Oletame, et meil on andmestik Netflixi filmide ja vaatajate reitingute kohta (skaalal 1-5):
| Visa hing | Terminaator | Bridget Jones | Jääaeg | |
| Hans | 5 | 4 | 1 | 2 |
| Grete | 2 | 1 | 5 | |
| Maria | 1 | 4 | 5 |
Juba peale vaadates (ja filmide sisu peale mõeldes) on näha, et Terminaatori ja Visa hinge reitingud on tugevalt seotud ning vastandlikud reitinguga Bridget Jonesile. Seda olukorda saaksime kirjeldada nii: a) iga film on mingist žanrist ja b) igale kasutajale meeldivad osad žanrid ja ei meeldi teised.
Maatriksi faktoriseerimine (matrix factorisation) aitab meil kvantifitseerida nii a) kui b): saame numbrilise kirjelduse (vektori) igale kasutajale meeldivate žanrite kohta ning iga filmi jaoks saame vektori, mis kirjeldab, kui palju filmis mingit žanrit on (see ei pea olema range jaotus – “Visa hing” võib olla 100% märul ja 5% armastusfilm).
Ja kus on maagia? Me ei pea teadma midagi ei žanrite, kasutajate ega filmide kohta – saame selle kõik automaatselt õppida ülaltoodud reitingutabelist. Vastava lähenemise nimi on arvamuspõhine filtreerimine (collaborative filtering) ja seda saab rakendada igasugustes soovitusmootorites: näiteks veebipoe toodetele (Amazon.com), artiklitele (New York Timesi koduleht) või muusikale (Spotify). Üks mu Google’is töötanud professor tegi nalja, et tehnika on nii levinud, et kõik Google’i insenerid on vähemalt korra sellise soovitusmootori kirjutanud.
Stiimulõpe
Stiimulõpet on kõige lihtsam selgitada arvutimängu näite varal: võtame Tetrise. Suvalisel hetkel mängu ajal on sul kolm võimalikku tegevust: liigutada klotsi vasakule, liigutada klotsi paremale või pöörata klotsi 90 kraadi. Kui suudad horisontaalse rea täielikult ära täita, saad punkte. Kui klotsid jõuavad maast ekraani ülemisse serva, on mäng läbi.
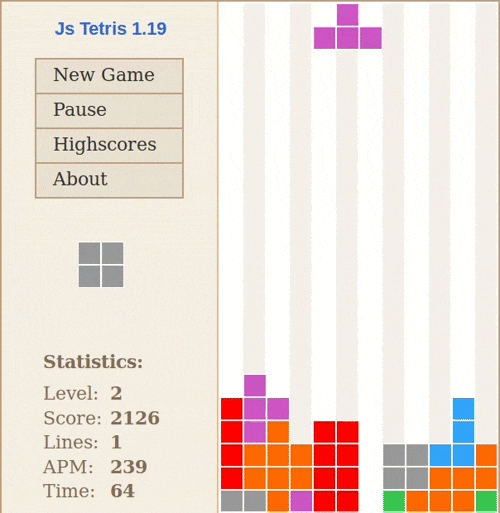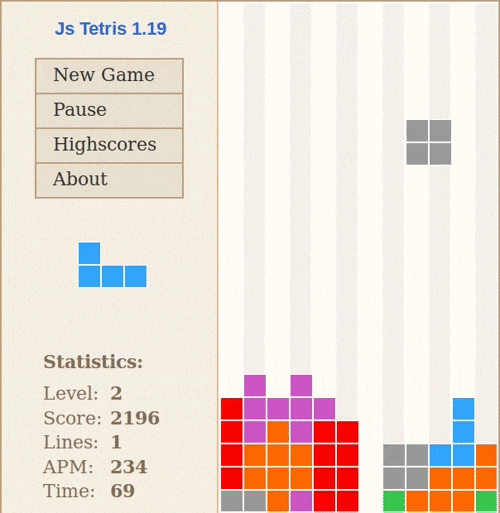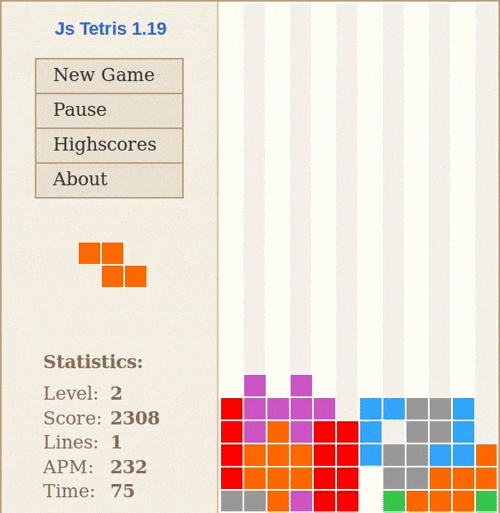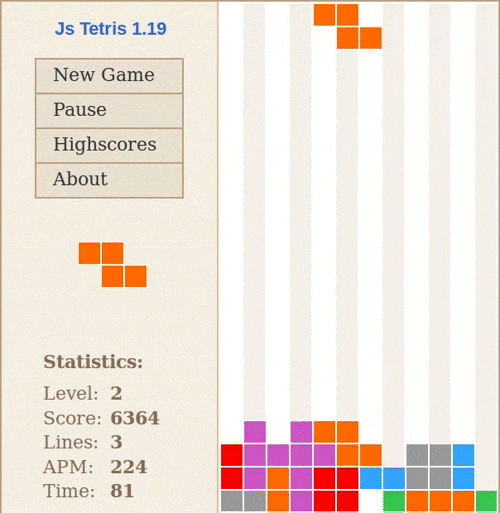
Stiimulõppe põhikomponendid on keskkond (Tetrise mäng), agent (mängija – see võib olla inimene või arvutiprogramm), preemia (reward – muutus skooris) ja tegevused (vasak, parem, pööra). Põhimõte on sama, mis koera treenimisel (koer on siin agent): kui ta teeb midagi hästi, saab maiuse.
Stiimulõpe peab toimuma laivis: kui juhendatud õppe puhul saame kergesti eristada õppimisfaasi ja rakendusfaasi, siis stiimulõppe puhul toimuvad need korraga: pärast iga tegevust näeme, kas keskkonnast tuli preemiat või mitte, ja uuendame vastavalt oma käitumispoliitikat (policy). Keeruliseks muutub see siis, kui preemia ei ole vahetu ja seega agent ei tea, milline tegevus täpselt preemiani viis – kui koer saab maiuse minut aega pärast käpaandmist, on tal väga keeruline aru saada, et preemia tuli just selle tegevuse eest.
Lihtne stiimulõppe ülesanne on artiklite soovitamine veebis: ülesanne on näidata meie lehele jõudnud kasutajale artiklit, millel ta klikiks. Kui kasutaja klikib, saab agent preemiat, kui ei kliki, siis ei saa. Oluliselt keerulisem ülesanne on mängude mängimine, aga selles jõudis DeepMind 2013. aastal murrangulise tulemuseni: paljudes ATARI konsoolimängudes oli inimesest parem nende ehitatud agent, mis nägi ainult ekraanipilti ja skoori ning ei teadnud reeglitest midagi. Allpool oleval GIFil mängib üht konsoolimängu agent TÜ arvutusliku neuroteaduse labori projektist, kus üritasime1 DeepMindi saavutust korrata toetudes nende poolt 2013. aastal avaldatud mitte väga detailsele artiklile.
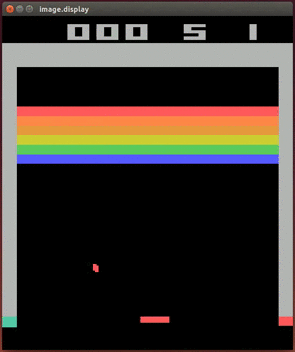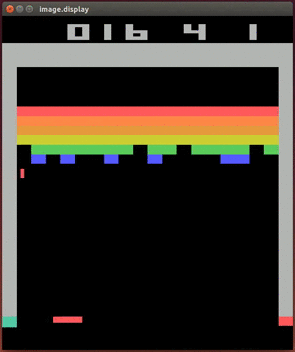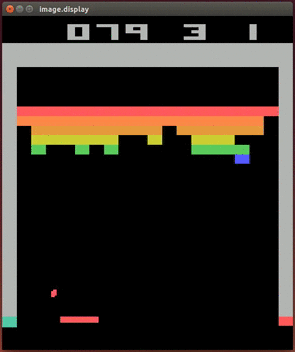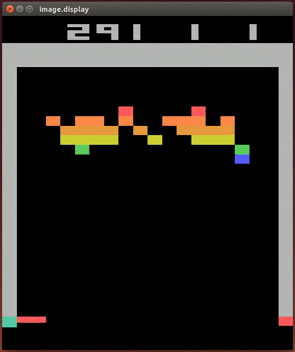
Isejuhtiva auto kontrollimise (nagu paljud muud ülesanded) saab samuti sõnastada stiimulõppe ülesandena, aga see on oluliselt keerulisem ja tõenäoliselt kasutatakse parimates isejuhtivates autodes stiimulõpet ainult mõnes alamsüsteemis.
Mis on sügavõpe ehk deep learning
Sügavõpe ei ole üks konkreetne masinõppe ülesanne, vaid lähenemine, mida saab kasutada nii juhendatud, juhendamata kui ka stiimulõppes. See on märg unenägu ja tõotatud maa, põhjusega. Sügavad neurovõrgud (deep neural network), mida enamasti sügavõppe all mõeldakse, on kõigi masinõppe lähenemiste hulgas parimad käekirjatuvastuses, piltidelt objektide tuvastuses, piltide kirjeldamises, kõnetuvastuses ja tekstianalüüsis – enamasti pika puuga. Näiteks suudab üks sügav mudel hirmuäratava täpsusega objekte tuvastada:

Sügavõpet kasutas DeepMind ülaltoodud ATARI mängude lahendamisel ja mängu Go mängimisel maailmatasemel. Sügavõpe on kasutusel Siris ja Google Assistantis hääletuvastusel, masintõlkesüsteemides (Google Translate) ja ilmselt kõigis parimates isejuhtiva auto süsteemides, aga ka näiteks potentsiaalsete ravimite leidmisel.
Kuigi sügavõpe töötab superhästi, nõuab see enamasti väga palju arvutusressurssi ja andmeid (aktsepteeritavaks tulemuseks >5000 andmepunkti, inimtasemel tulemuseks umbes 10 miljonit – allikas). Suurte neurovõrkude kasu tuleb Andrew Ng (Baidu masinõppe juht) sõnul välja alles väga suurte andmehulkade korral, kusjuures väikeste andmehulkade puhul ei pruugi tingimata neurovõrgud olla paremad klassikalistest masinõppemudelitest:

Lisaks on sügavad mudelid pirtsakad: sügavõppes on palju igasuguseid nupukesi ja lüliteid, mis peavad täpselt õiges asendis olema, et algoritm töötaks.
Eesti keeles saad neurovõrkudest veidi pikemalt lugeda Joonatan Samueli lühidast sissejuhatusest neurovõrkudesse.
Masinõpe versus…
…tavasüsteemid?
Tegelikult ei ole piir väga selge. Masinõppe üks põhilisi tunnuseid on, et programmi parameetrid õpitakse automaatselt – aga on täiesti võimalik kirjutada programm, kus automaatselt õpitakse ainult üks parameeter paljudest, kasutades täpselt sama matemaatilist lähenemist.
Data-driven development tähendab programmi testimist mingi andmehulga peal – see erineb test-driven developmentist, kus programm peab läbima mingi hulga ettemääratud teste. Selle andmehulga põhjal saab parameetreid õppida automaatselt, aga kui programmeerija muudab parameetrit käsitsi, siis toimub samasugune iteratiivne õppimine – tagasisidetsükkel on lihtsalt palju aeglasem.
…teised lähenemised tehisintellektile?
Tehisintellekti algusaastail (1950-1980) mindi masinõppest suuresti erinevas suunas.2 Ekspertide abil üritati kirja panna reegleid ülesande lahendamiseks ja rakendada loogikareegleid automaatsete järelduste tegemiseks. Üldiselt kasutati struktureeritumat ja loogikapõhisemaid lähenemist – see töötas mõnes ülesandes, aga enamasti ei suutnud lahendada ülesandeid, mis inimesele tunduvad imelihtsad (näiteks piltidest arusaamine).
Masinõppe suund on viimase paarikümne aasta jooksul nii kõvasti arenenud kahel põhjusel: esiteks on arvutusvõimsus oluliselt kasvanud ja teiseks suudame palju rohkem andmeid koguda ja säilitada (1990ndate keskel hoidis tüüpiline kõvaketas 1GB andmeid, mis mahutab umbes 200 kõrge resolutsiooniga pilti). Need muutused võimaldavad meil töödelda suures koguses andmeid, mistõttu saame “reeglid” õppida automaatselt ja ei pea üritama neid ise kirja panna.
Praktika
Liigume praktilisemate küsimuste juurde.
Kus pole masinõppest kasu?
Kõige tavalisem variant: kui andmeid on vähe – see sõltub ülesandest, aga tavaliselt on mõistlikuks analüüsiks vaja vähemalt sadu, eelistatavalt tuhandeid andmepunkte.
Teine variant: kui muudest mudelitest piisab. Pole ju mõtet palgata eksperti ja kulutada kuid sügava neurovõrgu arendamisele, kui lineaarregressioon (kõige lihtsam juhendatud õppe algoritm) lahendab ülesande ära.
Kolmas variant: kui see ei ole rahaliselt mõttekas. Kui ettevõtte kasum on miljon eurot, siis peaks masinõppemudel tõstma kasumit 5% võrra, et tasuks 2000-eurose kuupalgaga3 masinõppeinsener tööle võtta.
Kui suur on ikkagi mudelite andmenälg?
Masinõppe hiidude – Google’i ja Facebooki – sõnul ei maksa algoritmid masinõppes midagi, vaid väärtuslikud on andmestikud (seetõttu võivad nad rahus ka oma mudelite kohta artikleid avaldada). Eelduseks masinõppe rakendamisel on kvaliteetsed andmed, seega on väga oluline andmeid koguda, struktureerida ja märgendada.
See on vastuolus meie võimekusega teadmisi üle kanda: inimene suudab õppida uut tööriista (näiteks akutrelli) kasutama väga kiiresti, sest suudab üle kanda teadmisi teistest tööriistadest ja ülesannetest. Masinõppes on aga tihti vaja suuri andmestikke – see kõlab ebaefektiivselt.
Ühelt mudelilt teisele oskuste ülekandmist nimetatakse siirdeõppeks (transfer learning) ja see on praegu kuum teema, eriti sügavõppes. Juba praegu on võimalik väikeste andmehulkade abil ehitada häid mudeleid – selleks pead võtma mingit varem treenitud mudeli (mis on näinud palju andmeid) ja kasutama oma pisikest andmekogust, et kohandada mudel uuele ülesandele. Siiski ei saa me kõigis ülesannetes siirdeõppega hakkama ja sel alal tehakse aktiivselt teadustööd.
Kui raske on õppida masinõpet kasutama?
Ilmselt kõige keerulisem osa pole mitte teema ise, vaid matemaatilised alused: masinõpe toetub tugevalt lineaaralgebrale, matemaatilisele analüüsile ja tõenäosusteooriale. Nende baasil piisab ühest masinõppe kursusest (näiteks sellest legendaarsest Coursera veebikursusest), et masinõppega mängima ja katsetama hakata. Kuigi ilma matemaatilise aluseta on samuti võimalik mudeleid ehitada, on nii ilmselt raskem probleeme tuvastada ja uutest algoritmidest aru saada (ala areneb üsna kiiresti) – aga ma pole selles väga kindel.
Need matemaatilised eeldusained sisalduvad tüüpiliselt arvutiteaduse, matemaatika, statistika, füüsika jt reaalainete õppekavades, seega pole masinõpe ainult arvutiteadlaste pärusmaa.
Mulle tundub, et masinõppe ekspert suudab võrreldes algajaga a) paremini formuleerida ülesandeid – leida kohti, kus masinõppest võiks kasu olla –, b) aru saada, mis on tehtav, ja c) aru saada, miks asjad ei tööta. Kõik see tuleb praktikaga, seega otseteed masinõppe eksperdiks saamiseks ei ole.
Kes kasutavad Eestis masinõpet?
Paljud seda otseselt ei reklaami, aga näiteks Eesti masinõppe kokkusaamistel on oma kogemustest masinõppega rääkinud Skype’i, TransferWise’i, Starshipi, Adcashi ja Pipedrive’i esindajad.
Datasci.ee sisaldab nimekirja ettevõtetest, kes Eestis mingil viisil tegelevad andmeteadusega, sh masinõppega. Vist suurim konsultatsiooniettevõte on STACC (mis toetub küll (veel) peamiselt EASi grantidele).
Viited
2. veebruaril toimub Tartus üritus “Tehisteadvuse alged masinõppes“, kus Joonatan Samuel arutleb tehisintellekti tuleviku üle. Regulaarsem ja rohkem masinõppe praktikale suunatud ürituste sari on juba ülalpool lingitud Eesti masinõppe kokkusaamiste meetup.
Eesti andmeteaduse alase jutu ja üritustega kursisolemiseks sobib hästi Facebooki grupp Data Science Estonia, millega seotud veebileht datasci.ee sisaldab erinevaid ressursse Eesti andmeteaduse kohta.
Kui tahad masinõppe (populaarteaduslike) aluste kohta eesti keeles pikemalt lugeda, soovitan Andres Laane äsjailmunud raamatut “Tehisintellekt. Loomadest ja masinatest“, mis selgitab üldisemalt intelligentsete süsteemide toimimise aluseid (piir masinõppe ja tehisintellekti vahel on hägune).
Inglise keeles põhjalikumalt (ja tehnilisemalt) lugemiseks on hea põhiõpik Bishopi “Pattern Recognition and Machine Learning“. Sügavõppe jaoks on seni ainuke õpik äsjailmunud “Deep Learning“ vastava ala tippudelt.
Suur aitäh Kristjan Korjusele ja Allan Aksiimile oluliste paranduste ja täienduste eest.
Jaga: